[CS50] Week0 Scratch
1. What's computer programming ?
1.1 Input / output & the secret in the box
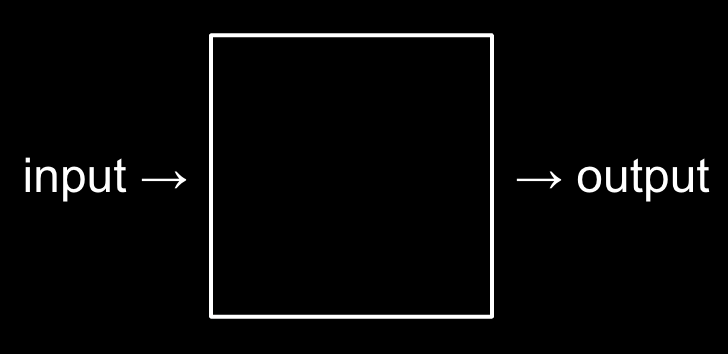
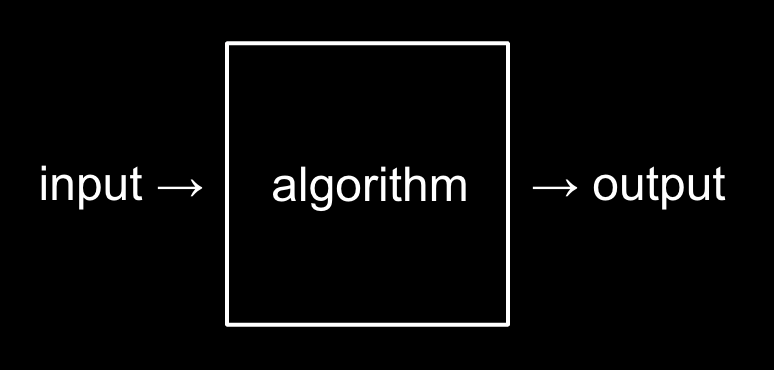
Computer programming is about taking some input and creating some output - thus solving a problem (the secret in the box is called "algorithm").
2. What's binary?
Computers today count using a system called binary. It’s from the term binary digit that we get a familiar term called bit. A bit is a zero or one.
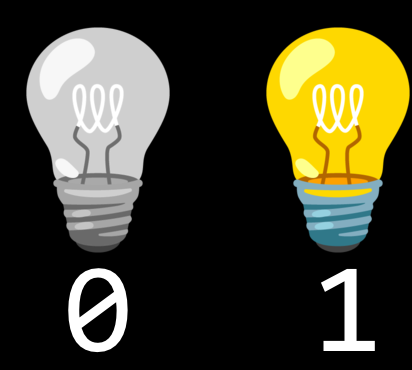
Computers only speak in terms of zeros and ones. Zeros represent off. Ones represent on.
2.1 二進位轉換
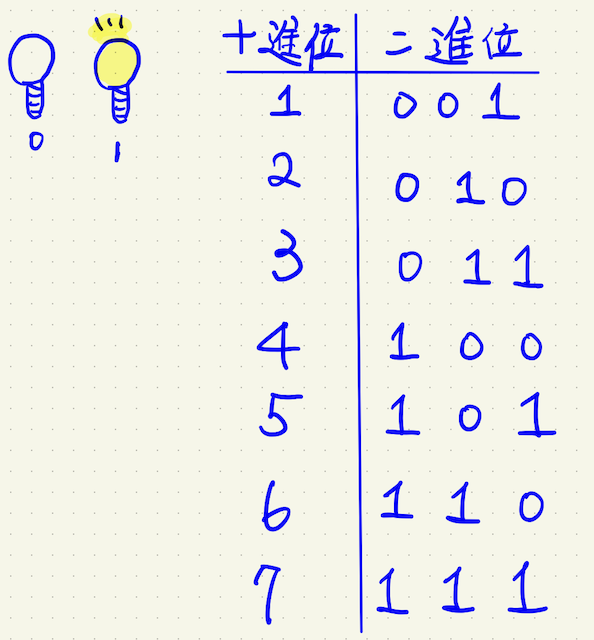
我們想將10進制的數字轉換為2進制,我們先想像一個位置只能放兩個數字(0或1),如果放滿了就要往前進位(逢2進位),例如10進制的1,由於只有一個數字,因此轉換為2進制便是'001'。 若要將10進制的2,轉換為2進制,因為原本的位址已是1了,再放一個就超過了,因此往前進位,便變成是'010'。
2.2Text
既然我們說電腦只認得binary(二進制),那麼我們是如何表示文字的呢?
ASCII & Unicode
電腦發展的早期,藉由ASCII code(American Standard Code for Information Interchange)的組合,我們可以拼湊出英文字母和簡單的常用符號。
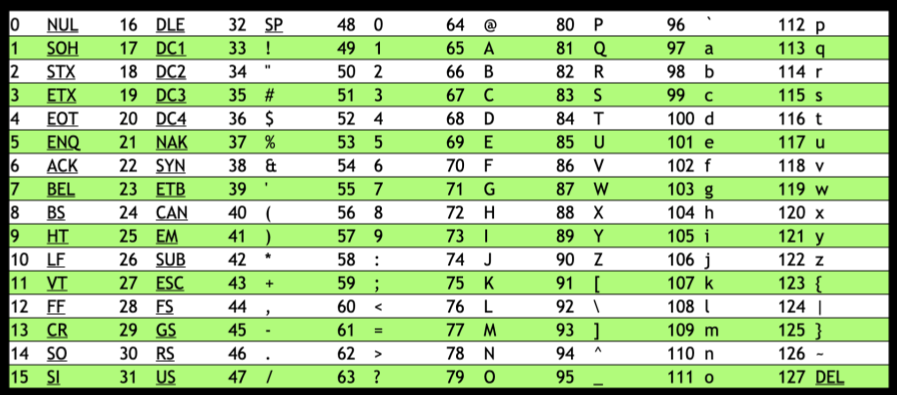
但是隨著電腦科技的進步與支持多國語言的需求,原先的ASCII code已不夠滿足原本的情境,因此後續發展出了Unicode來補足對多國語言和特殊符號的需求。
2.3 Emojis
Emojis 如何變換不同膚色

我們觀察到Emojis在不同的裝置上會有些微差異,表示emojis並非是用圖片的形式傳遞,那麼Emojis是什麼格式呢?
原來,Emoji膚色的不同是由在原本的Emojis Unicode後方加上補充膚色資訊的code來實現的。 這些code稱為皮膚色調修改符號(skin tone modifier),它們是一些特殊的Unicode,可以在基本的emoji Unicode後面添加,以產生不同膚色的表情符號。
例如,一個常見的按讚emoji是👍(拇指向上),要使其顯示為不同膚色的表情符號,可以在其後添加膚色修改符號,例如下方列表:
藉由在原本的Unicode後面補充膚色的資訊,即可達到在相同的Emojis變換不同膚色的效果
- 👍 :U+1F44D
- 👍🏻 :U+1F44D U+1F3FB
- 👍🏼 :U+1F44D U+1F3FC
- 👍🏽 :U+1F44D U+1F3FD
- 👍🏾 :U+1F44D U+1F3FE
- 👍🏿 :U+1F44D U+1F3FF
2.4 RGB
像素的組成
我們都知道光的三原色由 R(紅) G(綠) B(藍)所組成 那麼電腦要如何處理顏色呢?



每像素24位元(bits per pixel,bpp)編碼的RGB值:使用三個8位元無符號整數(0到255)表示紅色、綠色和藍色的強度(RGB各佔8位元)。這是當前主流的標準表示方法,用於真彩色和JPEG或者TIFF等圖檔格式里的通用顏色交換。它可以產生一千六百萬種顏色組合,對人類的眼睛來說,其中有許多顏色已經是無法確切的分辨。
3. What's Algorithm?
如果我們要查詢一個商店的電話,我們應該如何查詢電話簿?
- 從第1頁開始,1頁1頁,逐頁查詢
- 2頁2頁跳著搜尋
- 先看看想找的商店名稱的字母開頭是在電話簿的左半或右半部? 如果在右半部,那就表示我們無需查閱左半部。 用此方法一直持續的左 /右拆解電話簿直到找到我們要找的商店電話為止
前面我們評估的查詢電話簿方法,即可稱為是一種演算法。 我們藉由輸入想要查詢的商店名稱(Input),透過查詢方法(Algorithm),最後輸出查詢結果(Output),即是我們想藉由computer programming達到的效果。

3.1 Big-O notation
再回到前面的問題,如果我們要查詢一個商店的電話,我們剛剛提出了3種做法
- 從第1頁開始,1頁1頁,逐頁查詢
- 2頁2頁跳著搜尋
- 先看看想找的商店名稱的字母開頭是在電話簿的左半或右半部? 如果在右半部,那就表示我們無需查閱左半部。 用此方法一直持續的左 /右拆解電話簿直到找到我們要找的商店電話為止
那麼他們的查詢效率如何呢?
關於演算法的執行效率,可以使用 Big-O notation 來表示
Each of these approaches could be called algorithms. The speed of each of these algorithms can be pictured as follows in what is called big-O notation:
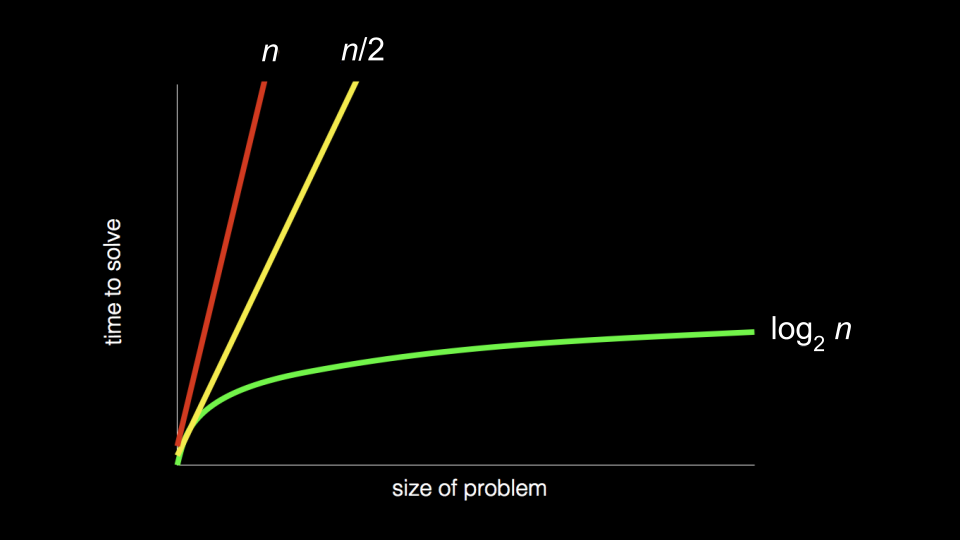
- First algorithm, highlighted in red, has a big-O of
nbecause if there are 100 names in the phone book, it could take up to 100 tries to find the correct name. - The second algorithm, where two pages were searched at a time, has a big-O of ‘n/2’ because we searched twice as fast through the pages.
- The final algorithm has a big-O of log2n as doubling the problem would only result in one more step to solve the problem.
國立聯合大學 資管系 陳士杰 老師 - 資料結構講義(http://debussy.im.nuu.edu.tw/sjchen/Datastructure/98/course01.pdf)
4. Pseudocode
The purpose of using pseudocode is that it is easier for people to understand than conventional programming language code, and that it is an efficient and environment-independent description of the key principles of an algorithm. (form wikipedia)
Pseudocoding is such an important skill for at least two reasons.
First, when you pseudocode before you create formal code, it allows you to think through the logic of your problem in advance.
Second, you can later provide this information to others that are seeking to understand your coding decisions and how your code works.
5. 小彩蛋 - 有趣的小發現
Q:在看影片時,一直有個疑問,為什麼影片中的人物可以去背得如此完美?
A:後來發現是因為講台後有一大片綠幕XD